US media-SNS, demand for big tech
Articles – Braking of unauthorized use of data
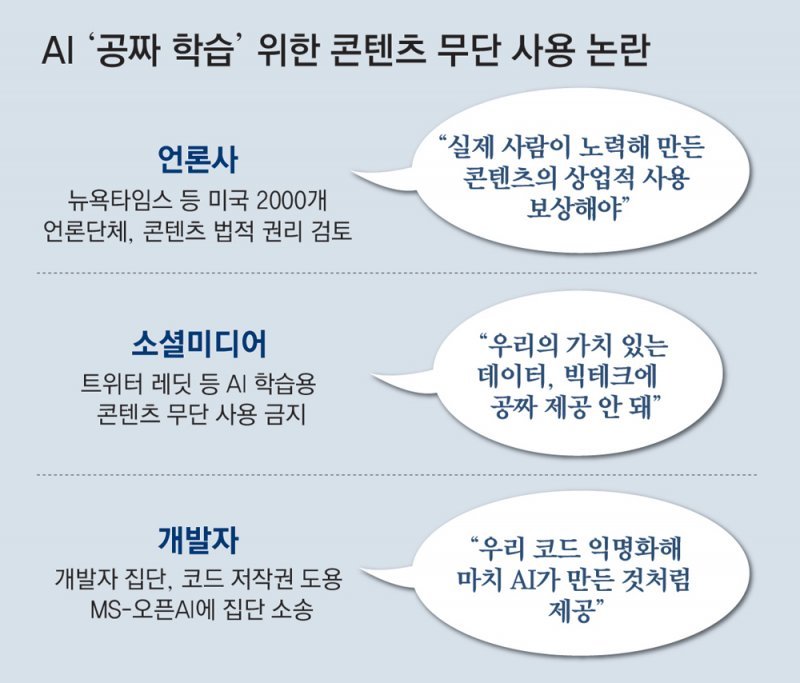
American social media Reddit, visited by 57 million people a day, put a brake on the free use of its content by big tech artificial intelligence (AI) and demanded that it “pay the cost.” Big Tech put a brake on the unauthorized use of media articles and social media conversations for AI learning.
Reddit said on the 18th (local time) that it has to pay for commercial use of conversation data on its site. The intention is to prevent Google, Microsoft (MS), and OpenAI from importing and using reddit content for free to improve generative AI accuracy. Reddit’s huge conversation data has served as a ‘tutor’ for the Large-Scale Language Model (LLM) that Big Tech is developing competitively.
Steve Huffman, CEO of Reddit, said in an interview with the New York Times (NYT), “The problem is that while creating value by scratching Reddit, it is not returned to users,” and “It is fair to make them pay.” In addition to social media, the News Media Alliance (NMA), which includes 2,000 American and Canadian media outlets, including the NYT, is also considering a collective response.
Unauthorized use of media articles for chat GPT learning
WSJ “You have to get a proper license”
Twitter-Reddit “Data Protection” API Monetization
“Content created by human effort and investment is constantly being used without permission (for AI learning).”
Daniel Coffey, vice president of the News Media Alliance (NMA), recently told The Wall Street Journal (WSJ) that he is investigating the extent to which news content is being used for AI learning. NMA is a media organization to which about 2,000 media outlets in the U.S. and Canada belong, including the New York Times (NYT).
The two most important factors in developing generative AI such as ChatGPT are the enormous amount of data required for learning and the outstanding computing power to digest it. The problem is that the ‘huge amount of data’ is content created by countless people. Examples include news articles, social media conversations and personal content, academic papers, and program development code. The core of the AI learning copyright controversy is whether it is appropriate to use commercially without permission even for content that has been released online.
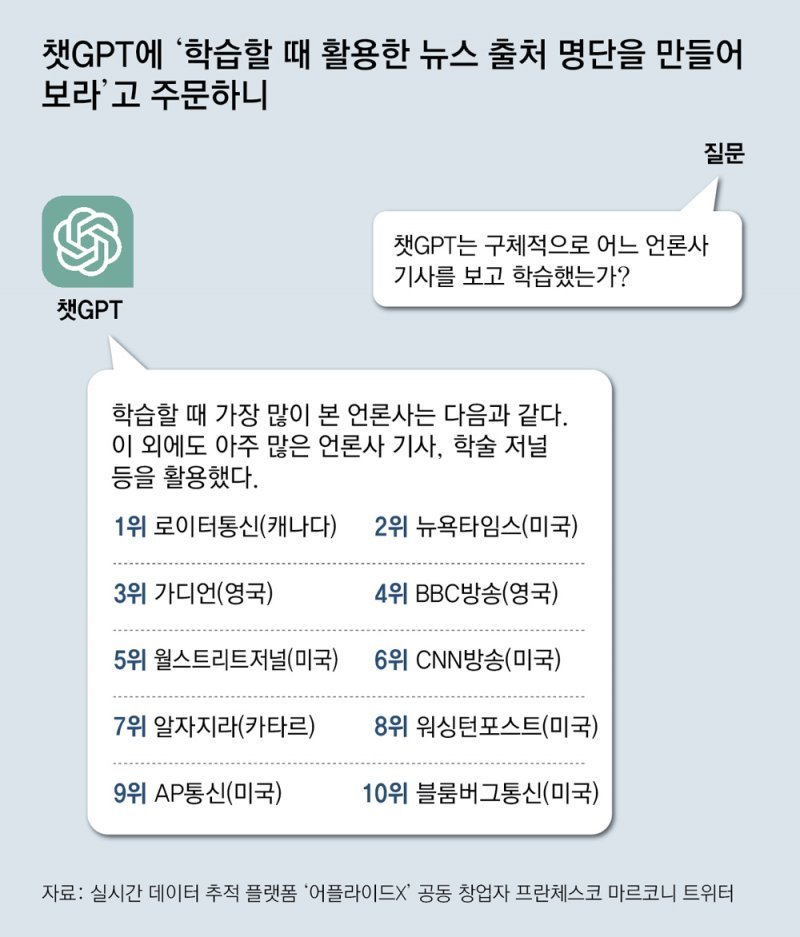
In February of this year, when a former WSJ reporter asked ChatGPT, ‘what kind of news did you use to learn?’, ChatGPT replied that it learned from many media outlets and academic papers, including Reuters, NYT, The Guardian, BBC, and WSJ. This reporter found out that the news of the press was used without permission when the actual open AI developed ‘GPT-2’ on GitHub, a developer code sharing space.
According to Bloomberg News, the WSJ is also known to be considering a lawsuit against OpenAI. WSJ parent company News Corp. told investors in February that “anyone who wants to use articles written by WSJ reporters for AI learning must obtain an appropriate license from us.”
US media companies are also raising issues about the fact that Microsoft’s Bing AI or Google Bard does not provide a summary of the media articles when answering user questions, and does not properly link them.
Not only the media, but also social media are protesting, saying, “It is unfair and copyright infringement for Big Tech to make money with our content.” Twitter CEO Elon Musk said in December of last year, “It’s no surprise, but I just found out that OpenAI can access the Twitter database for AI training,” and “I’m going to block it.”
Twitter eventually paid for an application program interface (API) that can access the database in February this year. Reddit, which had been operating free of charge since 2008, followed Twitter on the 18th with the condition of ‘paid for commercial use’. The NYT commented, “Reddit’s monetization policy is an important example in the movement of social media related to AI learning.”
{kind=link}
In November last year, an anonymous group of developers filed a lawsuit in the San Francisco Federal Court, California, alleging that Microsoft and OpenAI infringed copyright by using software development codes they posted online without permission.
Microsoft’s Co-Pilot and OpenAI’s codex, which are AIs that make development code easy, learn from codes on GitHub, etc., and then anonymize them and provide them as AI answers, which is why copyright has been infringed. In the complaint, they said, “When we share development code, we have been required to specify the author’s name or license,” and “However, AI disregards open source conditions and is randomly learning and distributing it.”
In response to the controversy over the unauthorized use of content, OpenAI CEO Sam Altman said in an interview with the US media, “If necessary, AI was trained through content trading. We are willing to pay for high-quality data in certain areas.” However, as the media, social media, developers, artists, and image companies are all protesting, controversy and lawsuits are expected to continue. When private information contained in personal content was exposed in responses, Italy temporarily suspended the use of ChatGPT.
The WSJ worried that “AI technology (which can learn large amounts of language data) is enabling industrial-scale theft of intellectual property rights.”
New York =
Source: Donga
Mark Jones is a world traveler and journalist for News Rebeat. With a curious mind and a love of adventure, Mark brings a unique perspective to the latest global events and provides in-depth and thought-provoking coverage of the world at large.